Summary by Sean Murphy
Master of Business Administration Program
University of South Florida, Spring 2003
Theory of Constraints Main Page | The
Goal | What is this thing called TOC?
Written in 1990, this book is still ahead of its time. The issue of data and information incongruence continues to be a hot-button issue in every boardroom. A "must" for every manager concerned with meeting the challenges of the 21st century. Goldratt examines the differences between data and information in a new light, and shows precisely how misunderstanding those differences can affect the quality of the decision-making process.
PART I (FORMALIZING THE DECISION PROCESS)
1. Data, information and the Decision process - How they relate
We are drowned in oceans of data; nevertheless it seems as if we seldom have sufficient information. Goldratt examines the key differences between data and information. Data is any answer while information is "the answer" to the question asked. In fact, he points out that what we call information systems are really just immense data systems. They tend to collect and store volumes of data and produce mammoth scores of reports - but fail to answer the questions we need to answer. The decision process itself is imbedded in any good information system and the decision process is changing. If we want information systems and not just data systems, we need to adjust accordingly.
Goldratt recounts an Israeli legend of an Army captain who decided to stop printing a certain report. This huge report was run periodically and distributed in paper copy to several locations. When the report ceased to exist, only one complaint was recorded…from the person who's job it was to neatly file the reports.
2. What a company tries to achieve
Just in time (JIT) is not just reduction of inventory on the shop floor or a Kanban technique - it is a new overall management philosophy. Theory of Constraints is not just bottleneck reduction on the shop floor or an optimized production technique - It is a new overall management philosophy. Total Quality Management (TQM) is not just about the quality of products or a mechanical statistical process control technique - it is a new overall management philosophy.
To begin to understand how this is so, we must answer the question, “why is an organization built?” From there, “who decides the goal of an organization?” Is it the customers, the employees, or the owners? Is it some other power group? In conclusion, Goldratt states that the goal of a company is solely in the hands of the owners, or shareholders. And from that, the goal of any organization is “to make money now as well as in the future.” To see how JIT, TOC, and TQM are new overall management philosophies, these fundamental points must be understood.
3. Getting a hold on Measurements
Measurements are a direct result of the chosen goal. We do not choose to measure “things” before we know the goal. Most companies judge their performance based on 2 bottom line numbers (Net Profit and Return on Investment). Another measure that is very important is the data found on the cash statement.
But these are NOT the measurements we are after. We are looking for measures that show the impact of local decisions. From a Gedunken (or a mental, “thinking” exercise) about a cash-making machine, we come up with several questions that lead us to local measures that impact the goal (if we equate buying a money-making machine to investing in a company).
a. What is the rate at which this machine makes money?
b. How reliable is this machine?
c. How much money is captured by the machine?
d. How much money will we have to pour into the machine on an ongoing basis to turn the machine’s wheels?
4. Defining Throughput
Throughput is defined as the rate at which the system generates money through sales. Through sales can be omitted and the definition can be used across all industries. In any case, throughput means bringing fresh money from the outside, whether through sales, investments, etc.
Two considerations are important to defining throughput. First are the costs of increasing the sales, investments, etc. If it costs $30 in materials to increase sales by $100, then throughput is increased just $70. The second consideration is the timing of the transaction. You can measure throughput at the point of sale (when the money changes hands) or by the accrual method of accounting (when the transaction is considered irreversible). Each possess up and down sides, but are not critical to understanding what throughput is. These concepts simply affect to what degree your throughput is actually increased or decreased.
5. Removing the overlap between Inventory and Operating Expense
Inventory is the money the system invests in purchasing things the system intends to sell. Traditionally, inventory is considered an asset. However, Goldratt views inventory differently. The question is how does inventory add value to the company? It only does so when we sell products (increase throughput).
Looking at inventory only as a means for increasing throughput creates problems in traditional cost accounting. You can reduce inventory and still improve customer service, meet or exceed production needs, and increases sales…but still fail the bottom line. Why? Because a reduction in inventory reduces the asset side of the balance sheet which lowers net profit. This requires a change in thinking by top management.
The reluctance of mid level managers to move away from the traditional way of measuring inventory (or anything really) stems from the saying: Tell me how you will measure me, and I will tell you how I behave. If you measure me in an illogical way…do not complain about illogical behavior.
Operating expense is defined as all the money the system spends in turning inventory into throughput. Money is invested in inventory and spent in operating expense. Note the distinction. When we buy oil for a machine, it is inventory. When we use the oil to lubricate the machine, it is operating expense. When we purchase material (raw materials) it is considered inventory. As we use the raw material, some is scrapped. That portion is considered operating expense. As a machine (asset) is used, some portion of it gradually is scrapped, which we term depreciation - removing it from inventory into operating expense.
6. Measurements, Bottom Line and Cost Accounting
Have we reached the point of fully explaining why we are dealing with a “new overall management philosophy? Not quite. The fundamental measures of throughput, inventory, and operating expense are used in conventional management. So, there must be more to explore.
The three measures relate to each other creating two relationships among each. Throughput minus operating expense equals NET PROFIT. Throughput minus operating expense divided by Inventory gives us RETURN ON INVESTMENT. Throughput divided by operating expense is PRODUCTIVITY and throughput divided by inventory is called TURNS. No new measures here…So, how can we justify TOC as a new overall management philosophy?
To help get that answer, we must look at cost accounting’s affect on organizations. When invented, cost accounting was a powerful solution to a huge problem. But, like all solutions, it was not the ultimate solution. In a dynamic environment, yesterday’s solutions become tomorrow’s problems. Cost accounting has created assumptions that (because of technology) have rendered it obsolete.
7. Exposing the Foundation of Cost Accounting
To judge a local decision, we must break down the measurements we have established. Throughput is just the summation of all the gain from sales of all the individual products.
T = ∑pTp
Where p = individual products
Operating Expense is simply the summation of the individual categories of operating expense (workers and managers time, banks for interest, utility companies for energy, etc.). Note that “products” are not a category of operating expense…you don’t pay money to a product. And money paid to a vendor is considered inventory. The formula looks like this:
OE = ∑cOEc
Where c = individual categories
Remember that the final judges for any local decision is NP and ROI. We may have a problem.
If NP = T - OE, then
NP = ∑pTp - ∑cOEc
This set of formulas makes us compare products and categories (apples and oranges). It becomes very difficult, if not impossible to see how a local decision will impact the net profit of a company. How will launching a new product impact sales of other products? We can’t answer that unless we know the impact the new product will have on the various categories of operating expense. Throughput may be high for the new product, but NP may go down any way.
Cost accounting was developed to help answer these questions. First, cost accounting admitted to searching for a very good approximation versus precision in getting answers. Second, the method is to make apples and oranges into apples and apples - thus allowing true comparisons. For instance, taking an operating expense like direct labor and breaking it into the products the labor is used for, allows us to consider it against throughput measures. This concept allows for ALLOCATION of the categories of OE across products. From there we can simplify our formulas into:
NP = ∑pTp - ∑pOEp
or, NP = ∑p(T - OE)p
This allows us to dissect a company into product by product classes. But the business world today has changed and cost accounting has been slow to react. They have not reexamined the fundamentals, the financial statement logic, to create new solutions. Instead, they have formulated ineffective answers like “cost drivers” and “activity-based costing.” We can no longer allocate based on direct labor. So allocating expenses at the unit level, batch level, group level, and company level is meaningless. These cannot be aggregated at their respective levels nor at the top. So why do it?
Remember that cost accounting solved our main purpose - the ability to have one classification of products and categories. That gave us the ability to make decisions. We need to be able to judge local decision’s impact on the bottom line. Simply expanding the number of classifications does not do that.
8. Cost Accounting was the Traditional Measurement
The financial community would gladly give up cost accounting if there was a “better way.” It is the other managers that hold on to cost accounting - primarily because of the nomenclature. For instance, operating expense of a product is product cost, yet we never have paid money to a product. Since Net Profit ONLY exists for the company, we can dispense with terms like product profit, product margin, and product cost. Sales managers could not live if these terms were abolished in practice!
The use of budgets is another example of this thinking. Corporate level uses profit and loss statements, but down at the lower, local levels of the organization, we use budgets. What happens when the net profit of the corporation does not match the net profit of the budgets? We call it variance and that makes them match.
Cost accounting and the terminology that goes with it has shaped the decision making of managers. The decision to drop a product is made using cost accounting concepts. Rarely is the impact of the decisions on the system ever considered. Just local product cost numbers. Product cost, product margin, and product profit are the basic language of industry. The entire business seems to be classified into a “by product” status.
9. The New Measurements’ Scale of Importance
Throughput, Inventory, and Operating expense continue to be the measurements. Maybe the key is in how we relate to them? We know cost accounting is now invalid. So where do we go from here? We still have to understand how this is all a new overall management philosophy.
The final judges are Net Profit and Return on Investment. Both are shaped by throughput, operating expense, and inventory - although not equally and all at once. Traditionally, operating expense is the most important measure, then throughput because both impact NP and ROI. But OE is more tangible to managers, so it ranks first. Since inventory only impacts ROI, it ranks third. Based on the way “cost” is emphasized in firms, this order of emphasis is precisely how local decisions are made.
Go back and review the 3 movements we are examining (JIT, TOC, and TQM). All feature a process of ongoing improvement. Also, the goal of any company is to make more money now and in the future. That said, what is the rank order of our 3 measurements? Since the focus is to limit inventory and operating expense, they are theoretically limited to zero. So improvement has some limit. Throughput is limitless. The continuous process improvement focus realigns our measurements’ importance: throughput, inventory, and then, operating expense.
How did operating expense lose ground to inventory? We chose NP and ROI as bottom line judges of success arbitrarily. If we chose productivity and turns, you see the shift in importance. Further, we must consider the INDIRECT cost of inventory (especially the time-related aspect of it) as featured in The Race . Inventory actually determines the future ability of a company to compete. Thus, all three movements (JIT, TOC, and TQM) recognize inventory’s importance.
TOC: Local optima do not add up to the optimum of the total.
TQM: It is not enough to do things right. It is more important to do the right things.
JIT: Do not do what is not needed.
10. The Resulting Paradigm Shift
The “cost” world looks at our organizations and systems as a series of unconnected outlets. Each is an opportunity for waste and “leaks” that are individually examined and “fixed.” Is this reality? Our organizations are connected systems where tasks and missions are carried our in synch until a sale is gained. This is the “throughput” world full of dependent variables.
In the throughput world the Pareto principle (80-20) turns into (0.1-99.9) rule. All systems are only as good as their weakest link. Statistically speaking, there is really only one weakest link in any system at one time (0.1%). This link is called the system CONSTRAINT.
TQM and JIT actually fall short in understanding that there is really one problem to deal with at a time. They focus on the Pareto principle at least (20% of the problems). They also moved away from cost accounting (good), but now rely on too many non-financial measures (not good). Non-financial measures do not help you judge the impact of a local decision on the organization’s bottom line. Remember, the goal is making money…so $$$ must be in the measurements! Since there is only one constraint at a time, these theories tend to measure too much anyway.
In the throughput world, constraints replace the terminology that products played in the cost world. As we look to launching new products, the only measure that matters is, “what is it we do not have enough of?” In other words, find your system constraints.
11. Formulating the Throughput World's Decision Process
Management makes a huge mistake by focusing a little bit on everything. That's a by-product of the "cost world." The "throughput world" shows us that we should only focus on the constraints. They determine the performance of the company. Are there any companies that have no constraints? Not likely - every chain must have at least one weakest link. There are 5 steps in focusing:
1. Identify the System's Constraint(s): Those things that we just don't have enough of that limit the system's overall performance. We need not rank them if there is more than one.
Just do not worry about what looks like a constraint if it does not have overall system impact (Goldratt calls these trivialities
chopsticks).
2. Decide How to Exploit the System's Constraint(s): Exploit is the key word. We must get the most
out of our constraints in an effort to eliminate them. If your market is the constraint
- set 100% on-time rate as an expectation and meet it.
3. Subordinate Everything Else to the Above Decision: Non-constraints must supply constraints with all they need and no more.
This is when you are truly managing the situation.
4. Elevate the System's Constraint(s): After Step 2, we may find that fully exploiting the constraint shows there was actually plenty of the
resource. But, if after Step 3, we still have a constraint, we need to add more and more to it until we do have enough (subcontracting, advertising, etc.).
5. If, in the Previous Steps, a Constraint Has Been Broken, Go Back to Step One: OK, you've broken the first constraint you've found.
Are you done? No! Many constraints are tied to policy (some archaic) that must be examined to reflect the new way of doing business.
6. If, in the Previous Steps, a Constraint Has Been Broken, Go back to Step 1, But Do Not Allow Inertia to Cause a System Constraint: Very
important warning. Most companies do not have physical constraints - they have policy constraints. Very few bottlenecks (capacity constraints) - usually production and
logistical policy constraints. This was the case described by the Goal. So, make sure to keep policy up to date with process.
12. What is the missing link? - Building a Decisive Experiment
Back to the issue at hand - what is new in our NEW OVERALL MANAGEMENT PHILOSOPHIES? The goal of an organization is to make more money now and in the future. Can we answer the question, "What will our net profit be next quarter?" We should be able to, shouldn't we? But, instead we can list the reasons (complaints) as to why we cannot answer that question. Are they nothing more than excuses? We seem to have 2 real problems - lack of information or not defining it correctly and the diverse approach companies take to making improvements. Maybe we need to do another Gedunken experiment:
The following is given:
Ours is a "Perfect Plant"
Two products P and Q
Defect Rate is Zero
Selling Price P = $90/unit; Q = $100/unit
Market Potential = Sales Forecast; P = 100 units/week; Q = 50 units/week
Each worker is available 5 days per week, 8 hours per day
Plant Operating Expense is $6000 per week.
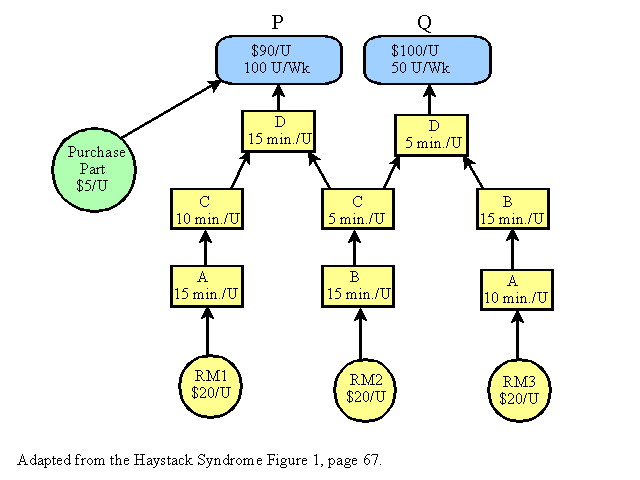
The Production/Engineering Diagram looks like this:
All data is given. All data precise. No excuses. Can we answer the question now, "What is the maximum net profit we will earn next week?" Do we have enough information? To solve this problem you will begin to see information in a whole new light.
13. Demonstrating the Difference between the Cost World and the Throughput World
Most people would solve the previous chapter’s question like this:
P: 100 units X ($90-$45) = $4500
Q: 50 units X ($100 - $40) = $3000
NP = ($4500 + $3000) – ($6000 “operating expense”) = $1500
Wrong. This calculation neglects the first step “IDENTIFY THE SYSTEM CONSTRAINTS.” Look at the load forecast for each resource. For A, the load placed by Product P per week is 100 units times 15 minutes per unit (1500 minutes). Product Q places an additional load on resource A of 50 units times 10 minutes (500 minutes). The load is a grand total of 2000 minutes and the availability of resource A is 2400 minutes per week. No problem.
Resource B - after doing the same calculations it shows that the demand for Resource B is 3000 minutes. This is a constraint. Note: The demand for C and D after doing the same calculations falls far below the system availability.
We cannot satisfy the entire market potential. Hence the wrong answer above. We must make a choice as to which products in which capacities to make. Most managers approach the problem from three angles: profit per unit, cost per unit, or time/effort per unit. If we examine each product per those criteria, we might decide to make more Q’s than P’s. We can sell 50 Q’s per week (1500 minutes). We have 900 minutes left over to make P’s. That gives us a NP formula of (50 X$60) + (60 X $45) = $5700. Subtracting operating expense ($6000)…we find out that we will loose $300 per week. That puts us in a position of promising NP of $1500 (first formula) and actually losing $300 per week.
This won’t do! We must go to the second step “DECIDE HOW TO EXPLOIT THE CONSTRAINT.” This forces us to offer P to the market first. The new product mix formula is (100 X $45) + (30 X $60) = $6300. Subtract out operating expenses ($6000)…we have a NP of $300.
The key impact of this throughput thinking is not in the world of production. They could care less how much they produce and when. The sales department will care if management makes them sell P’s ahead of Q’s. Sales (normally on commission) earn less for P’s…they favor selling Q’s. This is how “systems thinking” is a real life dynamic.
14. Clarifying the Confusion between Data and Information - Some fundamental definitions
What is data and what is information? Resource B is a constraint - data or information? For production - it is information. For the sales force…it is data. Sales would consider “Push P and only then Q,” as information.
Information is not simply the data NEEDED to answer the question…it is the ANSWER itself. More so, information is the answer to the QUESTION ASKED. Data can be further separated into “data” and “required data” - an important distinction.
Information is arranged in a hierarchal way. At each level, information is deduced from the data. Two conditions must be met to acquire information: data availability and decision process validity. The decision process will follow the five focusing steps introduced in Chapter 11.
Some working definitions:
INFORMATION: An answer to the question asked.
ERRONEOUS INFORMATION: A wrong answer to the question asked.
DATA: Any string of characters that describes something about our reality.
REQUIRED DATA: The data needed by the decision procedure to derive the information.
ERRONEOUS DATA: A string of characters that does not describe reality (might be a residual of an erroneous decision procedure).
INVALID DATA: Data that is not needed to deduce the specific desired information.
15. Demonstrating the impact of the New Decision Process on some Tactical Issues
We have come to the conclusion that we will Produce 100 P’s and 30 Q’s. That brings us to SUBORDINATE EVERYTHING ELSE TO THE ABOVE DECISION. What happens (in reality) if we ask our production managers to make 100 P’s and 30 Q’s? The result is idle time. It takes 15 minutes to make P’s and 10 minutes per Q. That is a total of 1800 minutes used out of 2400 minutes available. Our production manager won’t want to stay idle for 600 minutes. So, produce more? NO. The excess made won’t add to throughput…It’ll just become finished goods down the line (unused inventory).
Subordinate everything else to the above decision forces us to look beyond the results of local decisions to the impact a decision has on the system. Further, our work ethic seems to be “If a worker does not have anything to do, find him something to do.” Subordination as a concept runs counter to our normal way of thinking. We are familiar with the saying, “Tell me how you measure me and I will tell you how I will behave.” But, without fully understanding how the subordination concept works and explaining it to workers/managers, the new saying might well be, “Change my measurements to new ones, that I don’t fully comprehend, and nobody knows how I will behave, not even me.”
Goldratt offers an illustration of local measurements in terms of elevating the system’s constraints. He shows that in the cost world, a manager that offers a suggestion that increases processing time by 1 minute per part and costs $3000 to implement (buy a new fixture) would be fired. But under throughput world thinking, the manager who makes this suggestion really understands elevating the system’s constraints. How? Because if the manager (who in fact is in charge of a non-constraint) implements a change that makes his resource go slower, but frees up time on the system’s constraint (and increases overall throughput), he or she is a genius! The other aspect of this example is true as well…if the same manager wasted their time finding “cost reductions” for the non-constraint, the impact to the total system would still be meaningless. But, isn’t that how managers are rewarded today???
16. Demonstrating inertia as a Cause for Policy Constraints
Moving on, we now see our system’s constraints and we subordinated and elevated as needed. Our next step was to go back to step 1 and (at the same time) not let inertia cause policy constraints. There is a complex example of taking our products to Japan. They want just as many P’s and Q’s as we sell in America. All the costs of production are the same as in America, but the Japanese want us to sell for 20% less per each unit. Should we?
We can look at selling all the P’s we can make. Since we see that this new market will bear all we can make, maybe we should buy a new machine to make P’s. That eliminates the previous constraint (constraint broken). After all the calculations, we find that NP is just about $800 per week. But, have we let inertia take us in the direction of producing P’s (the most profitable product)? Reexamined, we see that if we increase production for domestic sales rather than sending so much to Japan… we can still have about 400 idle minutes on Resource A… and that will result in $1500 per week NP. That’s almost double the NP than if we simply bought the new resource and sent all the P’s over to Japan! The moral of the story is to go back to Step 1 when you break a constraint, but when you get to step 1, look at the system as a brand new system. Avoid the temptation to simply build on previous assumptions and let inertia create new problems. Ask, “which product contributes more, through the constraint?”
PART II (THE ARCHITECTURE OF AN INFORMATION SYSTEM)
17. Peering into the Inherent Structure of an Information System - First attempt
Information - the answer to the question asked. The most needed information relates to questions that cost accounting was supposed to answer. There is a missing link between data systems and information systems. This lays the groundwork for the discussion ahead.
Information is arranged in a hierarchal structure, where information at higher levels can be deduced from lower levels using a decision process. If we didn’t use a decision process, our needs would only be data. Our current data systems lack decision processes, or at least are based on erroneous decision processes from the cost world.
We reserve the term information system for those that are able to answer the question asked using a decision procedure. To construct an adequate information system, we must build the relevant decision process. We have already identified the five focusing steps. This is our starting point in building an information system.
A discussion follows about a simple inventory and ordering system for 2 products with different demand schedules, ordering schedules, and vendor lead times. In building the information system to address this issue and determine raw material levels, three major factors have to be considered - Frequency of delivery, the unreliability in consumption levels, and vendor reliability. Of course, a need for numerical evaluation must be built in as to the system as well.
18. Introducing the need to Quantify “Protection”
One of the pieces of the information system that Goldratt is discussing concerning inventory he calls “level of paranoia consumption.” This sounds much like the concept of Safety Stock from Operations Management theory.
In any case, to formulate this information, we will go through the five focusing steps. We will Identify the System’s Constraints, decide how to Exploit them, and Subordinate to them. Our first action will be to decide the procedure to get us to the five focusing steps. Is the process as generic as our five focusing steps (that is, work in any situation)?
We look at a make versus buy decision from the throughput world instead of the cost world and we see very interesting differences in the results. Product cost is NOT the way to make this decision. We Identify our constraints. Then we Exploit them - in this case, we do that by making the part in-house. The next step is Subordination. But what does that mean?
In Subordination, attention is focused on the stronger links in the chain. What this boils down to is simply what is the difference between protective capacity and ordinary excess capacity. The first, as Goldratt illustrates in this chapter, is desired to account for Murphy, or unexpected production outages on non-constraints. The second is waste. To fully capture this distinction in our operation, we must mandate our information system not only Identify and Exploit the constraints - but also distill for the actual events in our company some means for determining the level of Murphy.
19. Required data can be achieved only through scheduling and quantification of Murphy
Any information system that lives up to its name must be able to answer all the “what if’s” we have discussed in previous chapters. Unfortunately, much of this information is unavailable. So, to help build this information, we need to distinguish between 2 types of missing data:
1. Knowledge of what are the company’s constraints Current and future…physical not policy…found in incremental phases
2. The ability to simulate future actions - scheduling Who should do what, when, and in what quantities?
So how can we measure Murphy? Possibly, it can be measured only through an examination of the aggregate impact of the local perturbations. This is better termed Buffer Management because the few places where Murphy’s actions aggregate is in the inventory (safety stock) that sits in front of non-constraints.
20. Introducing the Time Buffer Concept
We have established that one way to protect against Murphy is to build in inventory to keep non-constraints running - and allowing us to fully exploit the constraint. Is this the only way? No. Another way is to use time to our advantage. For instance, we can start an order earlier (when possible) and if Murphy happens, we have some flex time in the system. Once the problem is resolved, we can continue operations - without excess inventory on hand. The interesting point is that either way of protecting involved an “early start”…you either pre-build inventory or pre-start a job order.
We are simply protecting the constraint. In our effort to exploit the constraint - make the most out of it - we find that excess inventory and early starts are equivalent. For this reason, the proper way to express the protection of the constraint is in TIME. We now refer to the excess capacity that is desirable as TIME BUFFER - the interval of time that we release the task prior to the time that we would have released it if we assumed that Murphy did not exist.
What determines the length of a buffer? We know disturbances will happen, just not when and for how long? The following graphs approximate the function of discrepancies.
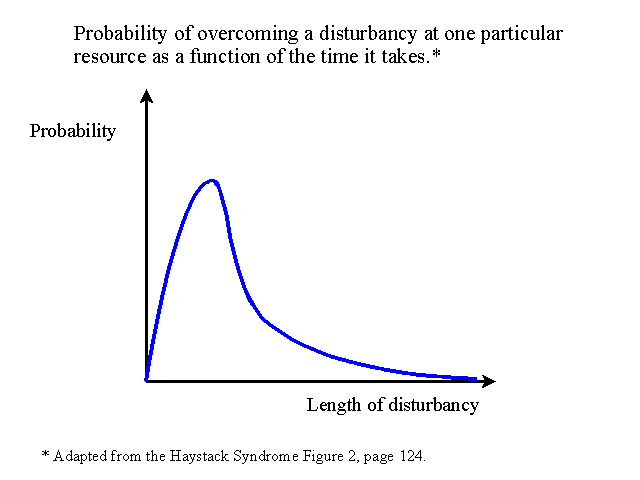
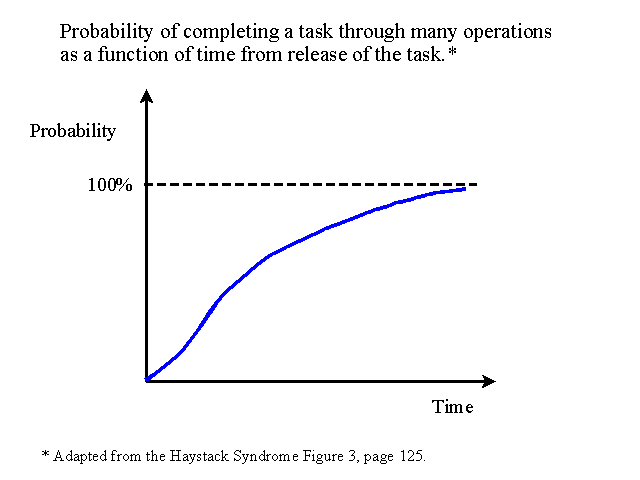
These graphs (particularly the second) show clearly that any disturbance can be overcome depending on the length of time we want to build in (size of time buffer). That length is a management decision. It involves a cost-benefit tradeoff in levels of time-related inventory (work in progress and finished tasks), future throughput, and operating expenses (expediting and control). It also effects throughput in our track record for delivery dates.
Who should make this decision? Top management??? No! The decision on the length of the buffers MUST be in the hands of the people directly responsible for the overall performance of the company.
21. Buffers and Buffer-Origins
More detailed statistical data does not necessarily help us get to the core problem - the need for protection from Murphy. There are 2 types of disruptions - one where there is an unexpected change (worker absent, tool breakdown, etc.) and another called Non-Instant Availability. This second type is when a resource is being used to do something else when we need it.
To establish buffer origins, we must look at the components of processing time. For almost every product, processing time is almost 100% buffer time. Processing time is actually negligible. So, Murphy accounts for virtually all of the buffer time needed. Is one type of Murphy longer than another? That’s unclear…
So how do we insert buffers into our plan? This begins the discussion of buffer origins. To determine our release schedule, we must measure backwards from the consumption of constraints to get our time buffers. The points in time for consumption of constraints is called the buffer origins. Again, these are simply time intervals connected to physical locations where protective inventory accumulates.
There is more than one type of buffer origin. There are Resource Buffers - right in front of the resource constraint that contain work in process inventories. There are Shipping Buffers - the shipping dock or finished goods warehouse. There are also Assembly Buffers - that contain pre-released parts from non-constraints to guarantee that other needed parts from the system constraint do not arrive at the assembly point and wait (the second type of Murphy).
22. First step in Quantifying Murphy
We need to quantify disturbances. Our method will be to devise a mode of operation that takes into account that at any given time, Murphy exists. And that our struggle with Murphy is a continuous one. Let’s look at which problem should we attack first, then next, then after that - in order of their impact (Pareto analysis)?
We choose to buffer only when something more important (throughput) would be lost had a disturbance occurred. Buffers are expensive (increased inventory, e.g.). How can we reduce the price of protection? We all know that if a process normally takes a week, we can expedite it in the case of an emergency. But to expedite everything creates chaos. Can we systematically use expediting? Sure. This gives us the Expediting Zone. Refer back to the Figure 3. The Expediting Zone is an area where we can speed up the arrival rates of resources. We choose to pick those that already arrive at a 90% rate to the buffer-origin. Note that the curve is relatively steep up to 90% probability. To get additional probability that a resource will get to the process - you must drastically increase lead-time. Anyway, choosing 90% means 10% of our tasks to a given resource will be expedited - very manageable. The result? Lower buffers, shorter lead time, and a more favorable trade-off between protection against Murphy and costs of doing so. Now that we have a way to concentrate the protection where it is really needed, maybe we can find a way to concentrate our efforts to reduce the need for protection.
23. Directing the Efforts to Improve Local Processes
We want to reduce the price paid for protection, we have to concentrate on the tasks that will arrive latest to the buffer-origin. Managing the buffers provides us with several benefits. It enables us to better determine the required length in accordance with the level of existing disturbances. It enables us to systematically and methodically to expedite tasks to shrink overall lead times. Then, tracking the locations where the delayed tasks are found and prioritizing according to the number of times each resource appears on that list (probably with an appropriate weighting factor) provides us with the desired Pareto list - the list that should be our productivity improvement guide. There is one other - even more important - benefit.
Maybe a resource pops upon our list and it has a superb process. This is because it does not have enough protective capacity. Quantifying Murphy is quantifying the buffer’s length and the amount of required protective capacity. We now have a way to monitor the expediting efforts - not in fire-fighting mode, but in a constructive way, geared to reduce overall lead time of all tasks. We might refer to this properly as Control - a crucial component to a good information system!
24. Local Performance Measurements
Measuring local performance (as we do now) by efficiencies and variances is counter-productive. We must find a better way. The answer is not in “non-financial measurements,” as some guru’s suggest. Remember the goal of any organization is to make more money now and in the future - so financial measures are imperative.
Also, remember that human nature is, “tell me how you measure me and I will tell you how I behave.”
Control is to know where things are versus where they should be and who is responsible for any deviation - measured via a procedure that continuously attaches a numeric value to each one of the areas responsible for execution.
Local performance measures should not judge the end result, but rather the impact the local area being measured has on the end result of the entire system. By this rationale - local measures are related to deviations to the enterprise plan. There are two types of deviations: not doing what was supposed to be done and doing what was not supposed to be done. The first impacts throughput and the second impacts inventory.
The unit of measure for deviations, which are clearly liabilities, is DOLLAR-DAYS or more accurately THROUGHPUT DOLLAR-DAYS because it relates to that system measurement versus the others (inventory and operating expense). Multiplying the number of days that have passed since a corrective action should have started by the dollars lost in sales gives a pretty accurate assessment of a deviation’s impact in financial terms. The measure works for the first type of deviation and in just about every business.
It makes sense to assign the resulting measure to the business unit where the process is stuck. At first, this seems unfair because they may not be responsible for the lateness - but the result to the system is exactly what we want. The center that inherits the problem will, in effect, expedite the resource like a “hot potato” to get it out of their department. This shows they are conscious of the Dollar-Days measure and the whole system benefits - not just a local department.
Will this behavior cause sloppy work as department push the “hot potato” out of their world and into someone else’s area of responsibility? Maybe we should assign a corresponding dollar-days measure to the quality control department. No doubt inferior products will be reported and sent their way. As the trend shows itself, it will be their job to remedy the situation (and guard against other departments shifting poor quality products out the door just to manipulate their dollar-days measure). The minute quality control sees a department simply passed off a poor product…they return the product to that department…along with the corresponding dollar-days. This actually defines TQM…Quality at the Source.
We still must deal with the second type of deviation (inflating inventory) and take on a local measurement that relates to operating expense. Those interested in these topics are directed to Theory of Constraints Journal, Volume 1, Number 3.
25. An Information System must be composed of Scheduling, Control and What-If Modules
A sort of review chapter…
Data is every string of characters that describes anything about reality. Information is the answer to the question asked. Data needed to derive the needed information is “required data.”
We must deduce information from the required data and any good information system will be able to integrate this decision process. Data Systems are those that supply readily available information while the term Information Systems is reserved for only those that supply information that cannot be achieved unless through a decision process.
A comprehensive information system must be built in a hierarchal structure. The top of which must be geared toward answering managerial questions that elevate constraints or prevent the unnecessary creation of new constraints. This level is referred to as the What-If stage.
We know now that we must first generate data on Identifying the System’s Constraint(s). We cannot start to identify constraints until we understand the scheduling aspect of an organization - hence the second stage of an information system, the Schedule stage.
Much of what we concern ourselves with in the Schedule stage relates to what Goldratt called Control. This concept refers to our desire to quantify Murphy (whatever can go wrong, will). We want to get a handle on the trade-off between inventory and protective capacity. Then we can answer What-If questions. We also can answer where to focus our efforts to improve processing and establish local performance measurements.
Thus far, we have 3 building blocks for an information system: What-If, Schedule, and Control. What-If is related to Schedule and Control as we have just described. But how are Schedule and Control related? There is a relationship between the Schedule and Control in that Control cannot be used until Schedule is functional. Remember, Control tells us where things are with respect to where they should have been. We control to limit deviations from the strategic plan…thus the schedule must exist first.
Deviations that impact throughput and deviations that impact inventory are deviations from our business plans. Our plans must include allowance for Murphy. Our Schedule block must predetermine an estimation of Murphy. Only in this way can the information system provide some realistic way of scheduling and controlling. The discussion thus far has laid the groundwork for us to build on for the rest of the text.
PART III (SCHEDULING)
26. Speeding up the Process
Time to outline the approach to the scheduling phase. The “MRP” has been considered a scheduling tool for some 30 years - it is not one, though. An MRP is a very good database though. But, they are very time consuming to establish. Does the time it takes to make a schedule render it worthless at some upper limit?
How can we shrink the run time of an MRP? We must look at every step - even the way the data is handled. Why does an MRP run take so long - computers are fast, right? Most manufacturing experts agree that the way our MRP applications work, most of the process is “shuffling data internally” characterizing MRP’s as “totally I/O bound.” The reason for that is related to technological limitations, Goldratt claims, that no longer exist. Programmers had no choice but to shuffle data between mainframes and smaller computers because of storage and processing capabilities. Since PC’s can more than handle the workload nowadays, you might see the continued MRP run process as one example of letting inertia cause a constraint…
27. Cleaning up some more Inertia - Rearranging the Data Structure
Product structure is usually broken down into 2 separate categories: Bill of Materials (BOM) and Routings. Both are descriptions of the journey that materials have to go through and have come about because of the problems we have had scheduling the material journey.
The first MRP’s ran on magnetic tape. The diagram below shows how a simple Sub Assembly and 2 Finished Products might be related. Sub Assembly A is required for both (Product A and Product B). Old magnetic storage tapes used when MRP’s were first constructed held one copy of the Sub Assembly. For each product that used Sub Assembly A, the tape would have to be “searched” through for the file. Very, very time consuming and inefficient.
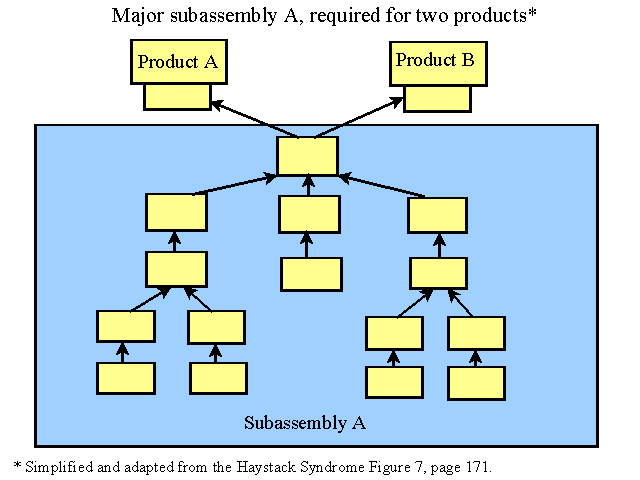
Another way to do it was to detail the Sub Assembly every time it was needed (for Product A and Product B, for example). Very labor intensive and inefficient as well. What happens if a change occurs in some part of the Sub Assembly…? All the Sub Assemblies must be updated.
The creation of BOM’s and Routing has alleviated much of these problems. In picture form, they look like this:
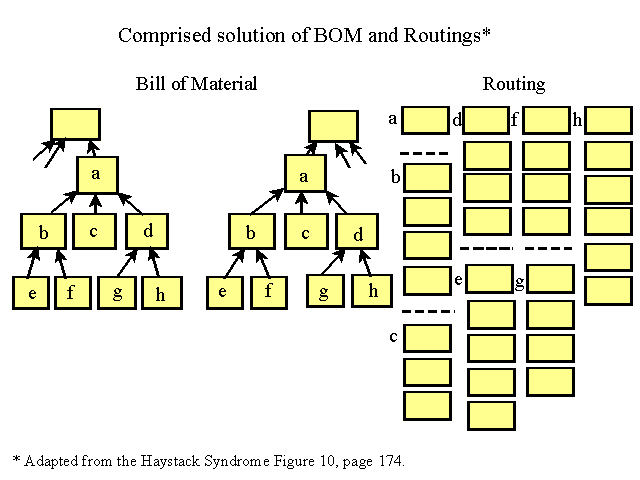
But they weren’t perfect. And while magnetic tapes gave way to floppy disks and vast hard drives of random access storage media, MRP structure stayed relatively static since BOM and Routing.
Goldratt examines another factor toward shrinking MRP run time in merging separately held “work-in-process inventory” and stores inventory.” Key to this concept is that computers execute instructions far faster than they “reach for disks.” Further, we must convert from the multi-file structure (BOM, Routing, etc.) to a suggested uniform, “task-structure net.” The idea is that the computer would only access the disks at the beginning of the run and hold all data in memory.
An information system helps managers at all levels answer “what-if” questions. They, and their specific data must be made available on a distributed, disseminated basis. A data system must be centralized, however, and information systems - fed from a single data bank - must be decentralized. We need not restructure the existing data banks to convert the data format. We must concentrate on the structure of the subset of data format and file layout that must become available for our information system.
28. Establishing the Criteria for an Acceptable Schedule
Where to start? A good schedule must be realistic. Our system must be able to carry it out - or IDENTIFY OUR CONSTRAINTS. Also, a realistic schedule should not conflict between the system’s constraints (it will be immune from disruption). When we identify constraints, we must check thoroughly that there aren’t any conflicts between the id’d constraints. Since the conflicts were unrecognized before, we can guess that the data required to resolve them is not clearly specified.
The information system, then, must:
Linear programming (and dynamic programming) do provide conflict resolving in scheduling - ignoring the lack of data and failing to highlight where the conflicts were encountered. Further it fails to protect against disruptions, in fact disregarding them. Still the method has been the cornerstone of operations research for the last 20 years.
The scheduling method of JIT - the KANBAN method - pushes the subject of conflicts from the scheduling phases to the execution phase. No guidance is available for selecting the number and content of the various cards to be located between workcenters - the full load of making the schedule work is placed in the floor personnel. MRP has given up on being realistic - it employs “infinite capacity.” Both JIT and MRP account for disruptions to the extent that they build in time to allow for them - more time than need to carry out the actual task itself (without disruptions). In short, each tries to immunize the schedule instead of the result of the schedule.
The need for a schedule to be protected against disruption is simply to ensure it is predictable…nothing more. There is one more (and most important) criteria of schedules. It must be measured (judged) by the same criteria we use to measure results - throughput, inventory, and operating expenses.
The end performance that the schedule indicates is judged by whether or not maximum throughput is achieved - exploitation of a company’s constraints. Second, the level of material inventory should be present only to guarantee the throughput. The schedule can only use overtime (Operating Expense) to protect throughput. If the information system does all this and if the user customizes the system contrary to these conditions - judge the end schedule accordingly - not the information system.
29. Identifying the First Constraints
Here’s where our scheduling should start. We must start by identifying something that is definitely a constraint - no guessing and hoping “buffer management” will save us. We are better off overlooking a constraint than choosing a non-constraint as a constraint. So, what can we identify as a constraint with a high-degree of probability to get us started?
Starting with a material constraint is risky. We need the detailed knowledge of the schedule we are trying to create to accurately identify them. Vendor constraints are likewise risky because in many, many cases - vendors are not the constraint. Resource constraints are not good first choices to target because most “bottlenecks” turn out to not be real bottlenecks and we need time to really decide whether a resource is a constraint or not…again, we need the schedule we are trying to create.
So, the only category left is market constraints - client orders. So, let’s use them. The only thing limiting us from making more money is the market demand. It is safe to assume that even if we do have internal constraints, we can still have market constraints. This is true is we have bottlenecks and where we have capacity constraints due to lack of sufficient protective capacity. Neither of these conditions will mask our market constraints and invalidate our process.
The only time the market is not a constraint is when we do not have to specify delivery dates to customers. Does that ever happen? Maybe if we only produce one product that is immediately grabbed by the market…very rare.
Next we need to exploit the constraint (the market). In this case, we need to simply meet our delivery dates. So, we move to the next step, subordinating everything else to client orders (the constraint). In this chapter - Goldratt chooses to circumvent this process and actually go back and look for additional constraints before subordinating to the market constraint because (in this example) the exploitation phase is inadequately illustrated.
To help us find bottlenecks (that by definition are time-dependent), we will set an arbitrary time interval of present date to the most remote due-date of our client orders. These due-dates are defined as the “schedule horizon.” From this we need to look at the workload for resources based on the schedule horizon. This can be misleading data…but we can’t give up. Let’s just concentrate on all orders whose due date is earlier than the scheduling horizon plus a shipping buffer. We will account for all the set-ups, size of the batches, etc. After all the needed calculations are accomplished for our resources, we can compare that to our schedule horizon. If the load placed on any resource is greater than its availability - we do have at least one bottleneck.
30. How to Work with Very Inaccurate Data
What if we collect all the data and we find we have a constraint - but it is really not? What if it is, but our data says it isn’t? In one instance, the first - it is dangerous to identify a non-constraint as a constraint. In the second case, the only harm is some computer processing time lost - in this day and age, not a big concern. The real question is how can our data show we have a constraint when we really do not?
A closer look at the data shows that of all the resources that seem to not have enough capacity, one resource (the one that takes 2 hours to process - the others take just 1) is most likely our resource constraint. But, this little bit of insight does not fully prove anything. If we are right, we have a conflict between the market constraint and the resource constraint. By definition, any resolution of this conflict will yield a degradation in the company’s performance. Is our conclusion based on erroneous data? We know it is almost impossible to keep accurate process times data for ALL processes. But, we can verify just a few…but which few?
For resource constraints, we based our calculation on computation of resource-type availability and on their required load. The availability was based on the calendar (usually uniform for entire organization) and on the data of number of units available from this resource. The number of resource units can be very inaccurate. Let’s assume we checked this data and found it all to be accurate.
We move to the data we used to calculate the load. We concentrate only on the process times that are required by this particular resource. This may seem obvious. But usually, when data accuracy is questioned, the normal response is to “clean the data to 95% accuracy.” Any system that goes in that direction misses the point of an information system to highlight clearly which data elements (out of the entire maze) should be checked, narrowing it down to a feasible amount to verify.
Our system (per this example) should display to the user a chart dealing with which tasks are absorbing what percent of the availability of our suspected constraint. We now need to match this up against our “big load tasks” (client orders). Avoid the temptation to store all these calculations. How much of it will be accessed later? Remember that computer speed in calculating is much faster than in storing/retrieving. Recalculate instead of storing intermediate results.
Once we pass the stage of verifying the very few data elements that caused us to suspect the existence of a resource constraint, we are ready to sort out apparent conflicts between the company’s constraints. Here comes the real test of our information system. Narrow the conflict down to its roots. Give the users clear alternatives so that they have no real difficulty choosing using just intuition.
31. Pinpointing the Conflicts between the Identified Constraints
Identifying a bottleneck (constraint) means that we cannot satisfy all orders on their respective dates - not enough capacity at least on one resource. Our information system does not have the required data to make the appropriate decision. Who should we short? By how much? What are the other alternatives? We need our information system to focus on the conflict AND allow the managers to make the decisions - not the computer.
We go to our five focusing steps. We have identified our constraint(s) and the conflicts (the market is one). We exploit that resource by making sure every order is one-time. Now, we must subordinate. Subordinating means ignoring any of the resources own limitations and concentrating on finding out exactly what we would like that resource to do to satisfy the constraint.
During this phase, you may be tempted to go into a “sophistication” process where you input, collect, and retrieve large, detailed data sets that may have very little meaning or relevance to the outcome. Avoid this temptation. We must deal with only the data we need. In our market constraint example - we allocate our stock based only on due-date. The ones with early due dates take precedence over later due dates - simple as that.
Next we want to know WHEN the resource is to perform. We know the due-date of the order and we know the shipping buffer. We should “release” the task from the resource constraint a “shipping buffer” before it’s due to be shipped. If we do that, we may find that many tasks conflict - we expect that. Maybe we should find which tasks conflict (relatively simple computer code based on the calendar of tasks) and adjust. On first blush, let’s take the conflicting tasks and merely push their processing start dates earlier. We will increase inventory - but that’s OK given the example. Having pushed the processing dates earlier, we reduce our conflicts - but create and infeasible solution with some processing start dates becoming yesterday. To fix this, we can adjust our processing dates forward to ensure all dates are future starts - again simple coding for today’s computers. In the end, we acknowledge the arbitrary nature of moving the start dates. Some tasks will be high-risk for Murphy. However, we have adjusted our focus to a manageable level - only a few tasks will require managers to pay close attention to disruptions.
32. Starting to Remove Conflicts - The System/User Interplay
At this point we have to make some distinction as to where an information system stops and user intuition must take over. In looking at our processing blocks, the information system will certainly guide us through a valid decision process, but human intuition is needed to avoid pitfalls. As the discussion in this chapter articulates and Goldratt’s series of Socratic type questions demonstrate, the point comes where the user must look at each “red block” and decide in what order to resolve them.
For instance, as we require our information system to forecast and attribute various set-up costs/times, it becomes apparent that without human sanity checks, we would end up with a resource constraint that spends most of its time in set-up, not production. The system user (in this example) must decide which blocks to “glue together” and combine steps.
Have we now removed the conflicts? Nope…we may have reduced them. It’s time for a bigger gun (overtime).
33. Resolving all Remaining Conflicts
Our information system should give guidance for allowing overtime per resource based on certain parameters, under rare circumstances, and ONLY to increase throughput. Overtime instructions are obeyed by the system without additional intervention from the user. From our present discussion, we have tried to reduce set-up time to free up capacity on our identified constraint. Once that attempt failed, we may look at overtime to accomplish what we need.
Overtime may help the task we desire it to. However, it also will help other tasks relative to their due dates. Depending on when we insert the overtime, if we cut it too close to the due date, there may be no effect on the task we targeted - but the tasks downstream are sped up. This relates to the idea that inserting overtime as far in advance as possible increases the likelihood it will work for the tasks it is intended to help. The balance is that you certainly do not want to insert overtime as a first resort, though. Note that one hour of overtime (if it does have an effect) will have the same effect on all resources.
Now we must insert overtime into our schedule at all points earlier than the first “red block” or task in danger of not being met. We insert until all the tasks are clearly feasible. If we keep inserting tasks and never get to a point where we can satisfy all tasks…then we get to a point where overtime fails to fix our resource constraints - then we need more drastic measures.
Now the user becomes the driver. He/She has to manipulate our information system to off-load a particular task to another resource, split the task and remove part of it to be done at a different time, or decide on a bigger, one-time shot of overtime. Regardless, any action taken for any task by the user will (remember) have major effects on all the tasks downstream. So a constant watch is needed as each individual action is taken.
In the end, the user can give up. Maybe they will have to live with some late orders. There may be nothing else they can do. The information system must be able to do this as well. It will do this by setting a new due date equal to the ending time of the latest among the “red block,” plus a shipping buffer. Missing a due date is bad enough…What we must not do is miss a due date without warning the customer.
We now have the first attempt at a “master schedule.” It’s a first attempt because we can’t be sure we have found all the constraints yet. It differs from the generally accepted concept in that it is created not only from data regarding orders, but also from data regarding the detailed schedule of the resource constraint.
The next step is to Subordinate everything else to the above decision. The actions of all other resources will need to be derived, so that they will safely support what we have already decided. At this stage we come across the concept of the DRUM. We have set the timeline for the schedule which sets the tone for how the process “marches along,” like to a drum.
When a second resource constraint is found - a new concept called RODS appears. Now is as good a time as any to define the concept. The length of a rod is one-half the resource-constraint buffer. When a resource constraint feeds itself through operations done by other resources, we need to protect the second (later) operation by inserting these rods. In a picture:
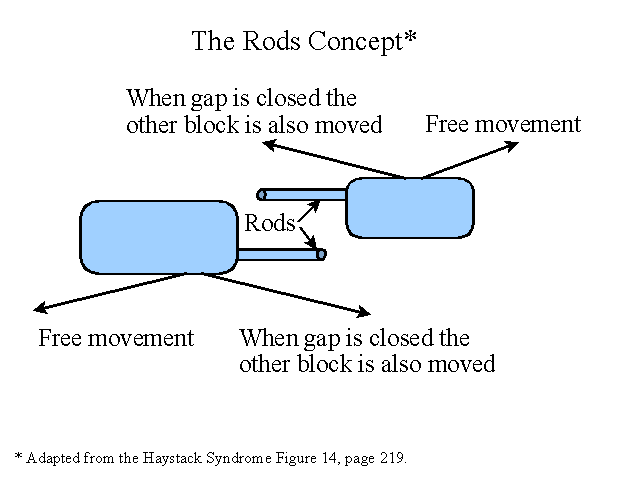
The movement of one block may cause the movement of many. The next segment of our journey is the subject of subordination.
34. Manual Subordination: the Drum-Buffer-Rope Method
The due dates for the orders and the exact dates for the resource-constraint operations have already been fixed. We do not have to worry about any mismatch between the dates. Any order is guaranteed to be processed by at least its shipping buffer (in emergencies, half the buffer). Now we have to fix the dates for all other activities.
First, determine the dates of release for materials. Our rule is that they should be released a resource buffer before the date they are to be consumed by the resource constraint. Subtract the resource buffer from the dates that have already been established at the drum.
For intermediate operations, we want the inventory they create to accumulate before the constraints - nowhere else. Only there does it serve its purpose as a protection against disruptions.
We are not telling non-constraint resources, “Do it on a certain day.” We are telling them to, “Do it as soon as you can, preferably the minute the material arrives, but if the material arrives before the specified date, please wait, don’t work on it, someone has made a mistake.
The resource constraints must rigorously follow the schedule. We also want those operations that use common parts to also follow the schedule very closely so they don’t push inventory to non-constraints that aren’t ready. For the other non-constraints, the schedule really tells them, “don’t do it before….” Not exactly a rigid command.
We have constructed the “drum” by pushing our tasks within the schedule backward and forward until they made sense according to the calendar. We have covered the operation feeding a resource constraint. We have covered the operations feeding free orders. And we have covered the operations between the blocks and orders. The only scenario left is operations that are not between blocks and orders and do not feed a free order. For these, we should follow the corresponding order by using the assembly buffer.
The schedule of an action should be derived according to the constraint date the operation feeds. This, and the chapter’s examples, describes the “drum-buffer-rope” procedure. We have now finished subordination - what clashes with reality will now occur?
After all the discoveries we have made, we may be at a point where the only thing to do is to postpone the corresponding instructions on the drum - postpone an order. How can it be that we are faced with a choice to remove conflicts only by decreasing throughput. Further, how can it be that we can increase inventory and operating expenses and still not fix the problem? Are our assumptions correct to begin with?
35. Subordinating while considering non-constraints’ capacity - The conceptual approach
The subordination process seems to be simply subtracting the various buffers from the dates already set by the drum. We also use the info on the length of the buffers. Does capacity have anything to do with the length of the buffers? Yes! Remember “non-instant availability of resources?” Sometimes, when work arrives, a resource may be busy doing something else and the work must wait a little while - not because of a bottleneck. Maybe we can get a handle on when these are going to occur.
To do so, we need to construct our schedule with an emphasis on moving backward in time. Reconsider the example of moving tasks (blocks) backwards and then forwards again to subordinate everything to our constraint. We need to build our scheduling system to do that. Doesn’t MRP do that already? No. At best, it resembles a zig-zag pattern over time - with a strong tendency to move forward over time.
36. Dynamic Time Buffers and Protective Capacity
We are tempted to start with the latest thing we are going to do (the latest order). More precisely, the latest order that is earlier than the horizon date plus a shipping buffer. We shouldn’t - we should start by allocating the stocks and based on due dates (the drum).
One dominant reason for a tasks lead-time is non-instant availability of non-constraint resources. Queuing phenomena results as people release material even earlier than the buffer dictates. Determining queues is very difficult. Most people use an “average queue time.” However, due to the inherent random nature of queues, this is a very misleading number. In using time buffers rather than queuing times - we improve considerably.
We can predict expected fluctuations in the workload. We can time the release of materials according to the expected load fluctuations. We wanted a mechanism to identify constraints - we got that and a significant reduction in inventory.
We rely on our information system to determine variable time buffer - we supply the fixed portion. We are basically going to use DYNAMIC BUFFERING.
A resource needs to have protective capacity to restore the damages caused by disturbances - not just at that resource but all the activities feeding it. The constraint is protected only by the content of the material residing in the buffer-origin. Note: we don’t protect just any inventory - only that which will be consumed by our constraint.
When we subordinate, we have to be careful that a resource is not running for too long before we enforce unscheduled time on it.
37. Some Residual Issues
Three chapters from the end…can we start to construct the subordination procedure, yet? No. First we have to spend some special attention on the “peaks” we’ve created by moving them backwards in time - that are the result of activity on the “red lane.” This type of situation will occur only when there is no “slack” - when the date of the block is not earlier than the date of the order minus the shipping buffer. With the right amount of slack - the red lane peak is not a problem. Not enough - we have to deal with the peak.
We can live with only half the buffer. Remember that the length of the buffer is key. For every hour above the available capacity on the date of the peak will cause the disruption to penetrate another hour into the buffer-origin. Let’s consider some overtime. Doesn’t work, let’s contact the user. They can authorize more overtime (the system suggests how much) or they can decide to off-load the task to another resource (the system will tell the minimum quantity) or postponing the date (the system must tell to what date).
What can the user do if these don't work? Do we have an additional constraint? The resource exhibiting this peak should be considered a constraint. We’ve done our job and now the system must resolve the conflicts between the already identified constraints.
Next open point. How do we take into account the time required to actually perform an operation? It’s the time to do a batch, found by multiplying the process time per unit by the number of units required, adding the set-up time, and then summing the results along the sequence of operations needed to do the task. If we do that, what happens?
We get a ridiculous result. We have to include the possibility of overlapping the batches between different operations. In the final analysis, the direct contribution of process times is even less than we stated earlier. If no problem of resource availability exists, as in a line, and Murphy does not exist, then the time it takes to complete the order is almost equal to the time required to complete the order at just one work center. Compared to non-instant availability and Murphy - this value is ridiculously small.
Is this the right formula? The direct contribution of the actual process time to the overall lead-time is the time to process the batch on the longest operation, plus the time required to process the batch at operations that cannot be overlapped, plus the time to process one unit at all the other operations. Let’s ignore set-up time because saved set-up is saved time, not money. If we find set-up time is limiting a resource, we will identify it as a constraint. But it is irrelevant to our discussion right now. Under these conditions, set-up time doesn’t affect throughput. In fact, reducing it increases inventory at non-constraints if we are not careful. It has no effect on operating expense - in our example, only overtime has that effect.
Now can we start to build the subordination mechanism?
38. The Details of the Subordination Procedure
We have all the tools needed to build the subordination process. The chapter describes a very technical procedure. There is one important guideline - to be very consistent in moving ONLY backward in time.
First, the system must be concerned with “current date.” It doesn’t want to “leave anything behind” - i.e. move from the current date without a very good reason. What makes us move? Each operation.
We need an interval of time to represent the sensitivity of the system. Anything less than this interval can be ignored as a reason for moving forward. Our example lends itself to a one-daytime interval (based on due dates).
This gives us 3 categories that will necessitate a move in time: the drum, the buffers, and the peaks of overload. We need to install “reminder lists” in our system. It should contain the entire drum - the due-dates of the orders and the ending time of the resource constraints’ blocks.
The subordination process…start with the highest entry on the list (likely an order) and dive from there. Go to the feeding operations, subtract out shipping buffers. Identify the operations that directly feed the order and put the corresponding notes on our reminder list.
Follow these steps and eventually, we’ll pick an operation, not just an order from the list. Calculate the load that it represents and adjust accordingly the current available capacity of the resource which is supposed to perform that operation.
As we continue to dive down, we will encounter one of 3 situations:
When no conflict has been observed at the end of subordination, we will repeat the entire last round of subordination and finalize the schedule. We will continue to follow this basic process and use the special guidelines developed in the last 2 chapters to deal with the special cases.
39. Identifying the Next Constraint, and Looping Back
We probably have some resources that are overloaded after the first day, since we’ve completed the subordination stage. There may be a lot of mountains of overloads at our resources and we might be tempted to misidentify new constraints. We must be patient. First, we need to go back and try and minimize the overload by using set-up savings, permitted overtime, and half-buffer, forward shoveling - sound familiar? Then consider the magnitude of the overload based on its effect on the overall system. Again, the user can take steps to overcome an overload…so be careful when trying to identify new constraints. Remember identifying a constraint means an increase in inventory (additional protection).
If we do identify a new constraint, the issue becomes the relationship between the first constraint we found and the new one we found. Goldratt refers to the new blocks and the old blocks (the jobs feeding the new constraint and the jobs feeding the old constraint). We have a need to define “time rods” to understand what to do next.
Time rods are equal to the length of half a resource buffer, and are sensitive to the date of the old block. The date for a time rod is what an iron wall is for a regular rod. Now we can find any possible conflicts between constraints.
The system for finding the conflicts between constraints as described several times in the text, happens over and over until all the overloads on the first day are resolved - all the constraints have been identified, exploited, and subordinated to, and no known conflicts have been left for the floor personnel to resolve.
Goldratt as a caution against thinking that what we have done so far ends the discussion offers a corollary situation. In sum, there are situations where a firm has one resource constraint feeding another resource constraint and it still may be in a system without any interactive resource constraints. As we have used market constraint as our first constraint, we have to realize the constraint may act on each resource differently and thus show the caution of Goldratt as having merit. In fact, we need to encourage this situation because it leads to increased throughput.
We have now finished the first phase of our information system - the scheduling. But we are by no means ready to move on to automating the control mechanism though.
40. Partial Summary of Benefits
A. Performing net requirement - finding how many units have to be produced at each point - a matter of seconds of time.
B. A dynamic, all-encompassing length of the run times.
C. Sales will get a pre-warning
D. The ability for Sales to communicate with Production managers (for instance)
E. Process Engineers and Quality Managers will be able to point to the processes that need to be improved
- rather than to workcenters that don’t have enough protective capacity
F. Top Management - since the system by definition does not consider policy constraints- the system is immune and durable. If “the schedule cannot be followed,”
then we can be sure we have a policy constraint and top management will have to agree.
__________________________________________
Related summaries:
Corbett, T. 2000. Throughput accounting and activity-based costing: The driving factors behind each methodology. Journal of Cost Management (January/February): 37-45. (Summary).
Goldratt, E. M. 1990. What is this thing called Theory of Constraints. New York: North River Press. (Summary).
Goldratt, E. M. 1992. From Cost world to throughput world. Advances In Management Accounting (1): 35-53. (Summary).
Goldratt, E. M. and J. Cox. 1986. The Goal: A Process of Ongoing Improvement. New York: North River Press. (Summary).
Goldratt, E. M., E. Schragenheim and C. A. Ptak. 2000. Necessary But Not Sufficient. New York: North River Press. (Summary).
Hall, R., N. P. Galambos, and M. Karlsson. 1997. Constraint-based profitability analysis: Stepping beyond the Theory of Constraints. Journal of Cost Management (July/August): 6-10. (Summary).
Huff, P. 2001. Using drum-buffer-rope scheduling rather than just-in-time production. Management Accounting Quarterly (Winter): 36-40. (Summary).
Louderback, J. And J. W. Patterson. 1996. Theory of constraints versus traditional management accounting. Accounting Education 1(2): 189-196. (Summary).
Luther, R. and B. O’Donovan. 1998. Cost-volume-profit analysis and the theory of constraints. Journal of Cost Management (September/October): 16-21. (Summary).
Martin, J. R. Not dated. Comparing Dupont's ROI with Goldratt's ROI. Management And Accounting Web. Comparing Dupont Goldratt ROI
Martin, J. R. Not dated. Comparing Traditional Costing, ABC, JIT, and TOC. Management And Accounting Web. Trad ABC JIT TOC
Martin, J. R. Not dated. Drum-Buffer-Rope System. Management And Accounting Web. Drum Buffer Rope
Martin, J. R. Not dated. Global measurements of the theory of constraints. Management And Accounting Web. TOC Measurements
Martin, J. R. Not dated. Goldratt's dice game or match bowl experiment. Management And Accounting Web. Match Bowl Experiment
Martin, J. R. Not dated. TOC problems and introduction to linear programming. Management And Accounting Web. TOC Problems Intro To LP
Rezaee, Z. and R. C. Elmore. 1997. Synchronous manufacturing: Putting the goal to work. Journal of Cost Management (March/April): 6-15. (Summary).
Ruhl, J. M. 1996. An introduction to the theory of constraints. Journal of Cost Management (Summer): 43-48. (Summary).
Ruhl, J. M. 1997. The Theory of Constraints within a cost management framework. Journal of Cost Management (November/December): 16-24. (TOC Illustration).
Westra, D., M. L. Srikanth and M. Kane. 1996. Measuring operational performance in a throughput world. Management Accounting (April): 41-47. (Summary).
